How to create powerful e-commerce search
Adding basic search to an e-commerce store is easy. Building great, measurable search experiences — and iterating high performance product discovery — is very difficult and often requires an entire team of search engineers.
We set out to change that. Our goal was to make a service to not only streamline the construction of great search but also the analytics and data workflows to create an ongoing flywheel of continual improvement. We wanted to put that power into the hands of any developer.
This article is a step-by-step guide into how you can build an amazing search experience — from spelling correction to NLP. We will show you how it’s possible to easily add everything from search basics to the most advanced, Google-like search features for your site.
Here’s (below) what the final experience will look like.
You can see the final search experience and try it yourself here.
Now let’s see how it’s done. Here are the steps we’re taking.
Getting started
There are few initial steps involved to get search.io search off the ground:
Import some data to help define a schema
Configure pipelines
Sync data
Generate a user interface (UI)
Connect data feedback to improve ranking and performance automatically
We will walk through each of these below.
Defining a schema
Schemas are all about performance. If you aren’t convinced we wrote an article on schema vs schemaless just to convince you 😉
You can do this a) manually in our admin console b) via our API or c) via uploading a sample record during your collection setup, or d) using a connector. This example used option b.
Note: If you’re using our website crawler, Shopify, or another connector this will happen automatically.
Configure pipelines
The configuration of an intelligent search algorithm can be extremely complicated. So, we re-imagined how engineers can build search by creating pipelines. Pipelines break down search configuration into smaller pieces that can be easily mixed, matched, and combined to create an incredibly powerful search experience. Pipelines are highly composable and extendable. You can read a quick pipeline overview here and more specific details related to this example below.
There are two kinds of pipelines to consider: Record pipelines and query pipelines:
Record pipelines define how your product data is processed on ingest
Query pipelines define how your queries are constructed
search.io automatically generates initial pipelines for you that you can modify or append later on via our built-in pipeline editor. When you first set up search.io, the auto-detecting onboarding flow allows you to:
Mark which fields are most important in ranking
Select how to train autocomplete and spelling
Generate a schema and initial pipelines
There is much more you can do with pipelines, which is somewhat expanded on below, but it’s worth noting you also don’t need much to get started.
Query pipelines
Query pipelines define the query execution and results ranking strategies used when searching the records in your collection.
Steps in a query pipeline can be used for:
Query understanding - query rewrites, spelling, NLP, etc.
Filtering results - based on any attribute in the index. For example location or customer-specific results.
Changing the relevance logic - dynamically boost different aspects based on the search query, parameters or data models
Constructing the engine query - as opposed to the input query, the engine query is what is actually executed, it can be extremely complex but you don’t need to worry about that!
Pipelines allow highly complex queries to be automatically constructed by chaining simple step-based logic together.
Query pipelines can also be A/B tested to continuously improve search performance based on business knowledge or machine learning based feedback.
Let’s walk through just a few of the customizations you can add to search using query pipelines. Below are some explanations of step configurations used in this example.
Field weights
Field weights allow different fields to be worth more when searching. For example the product name is probably a more valuable match than description.
In this case we’ve set the priority order: name, description, brand, ...
Right out of the gate this will start to optimise to what users expect. But it’s really just a starting point.
# Index lookups
id: set-score-mode
params:
mode:
const: MAX
id: index-text-index-boost
params:
field:
const: title
score:
const: "1"
text:
bind: q
id: index-text-index-boost
params:
field:
const: body_html
score:
const: "0.06125"
text:
bind: q
id: index-text-index-boost
params:
field:
const: vendor
score:
const: 0.5
text:
bind: q
id: index-text-index-boost
params:
field:
const: product_type
score:
const: 0.25
text:
bind: q
id: index-text-index-boost
params:
field:
const: tags
score:
const: 0.125
text:
bind: q
id: index-text-index-boost
params:
field:
const: image_tags
score:
const: 0.06125
text:
bind: q
id: index-text-index-boost
params:
field:
const: variant_titles
score:
const: 0.06125
text:
bind: qSpelling correction
Spelling is hard! If you’ve tried a fuzzy match in other search engines you would know it’s underwhelming. It also typically slows things down a lot!
The nice thing about search.io spelling is that it’s not only very very fast, it’s also much smarter than a standard fuzzy matching. You can add spell correction via pipelines using a few lines of YAML.
# Spelling
id: index-spelling
params:
phraseLabelWeights:
const: query:1.0,title:0.05,vendor:0.05,product_type:0.025,tags:0.025
text:
bind: q
id: synonym
params:
text:
name: qBelow are sample queries showing how missing characters are handled seamlessly.

The nice thing about search.io spelling is that it also learns over time. As people execute more queries the suggestions and autocomplete begin to better understand the most likely suggestions your customers want.
Business boosts
Next part is looking at business metrics and how they impact ranking. You may want to promote items that sell more frequently, have inventory in stock, have higher user ratings, or anything else you can think of!
One example is shown below showing a simple linear boost for items that sell more:
id: range-boost
title: bestSellingRank is important -> lower is better
params:
end:
const: "0"
field:
const: bestSellingRank
score:
const: "0.1"
start:
const: "10000"Initially boosts like this are defined by the business, but as more people search different options can be A/B tested and also real performance data begins to feedback and improve the ranking (see below).
So far we’ve seen how everything can be globally ranked in an initial sensible order (same logic applies to all queries) based on simple logic.
Now let’s see how more targeted logic can be applied to specific queries.
Gmail-style filters
Want to add Gmail-style filters to your search bar? For power users these are amazing. See below where the in:cheap syntax is used to filter to lower priced items. This example is contrived, but shows how easy this is to do with pipelines:
The logic here is interesting and only requires the simple addition of two pipeline “steps”:
id: string-regexp-extract
title: gmail style in:tag-name style filters
params:
match:
bind: in
matchTemplate:
const: ${inValue}
outText:
bind: q
pattern:
const: in:(?P<inValue>[a-zA-Z_\-]+)
text:
bind: q
id: add-filter
title: in:cheap
params:
filter:
const: price_range = '1 - 50'
condition: in = 'cheap'
These two steps sequentially perform two functions:
The “in:<match>” pattern is used to look for the Gmail style filters. The “match” is transferred to a new pipeline param called “in”.
A filter is added to look for the situation where in = “cheap”. If this occurs then a filter is added to the query to filter out things that are not cheap!
Below illustrates the transform:
Before regex step | After regex step |
{ "q": "phone in:cheap" } | { "q": "phone", "in": "cheap" } |
Note:
inis just an example. You could look forhas,fromor anything you like.Many additional filters can be added for all the other potential values here. It could be
in:saleor anything else.
Natural language parsing
We have two ways to do this, a) basic pattern matches and b) more complex models. This example uses the first option to show how some basic capabilities are easily addressed:
The code for this is a little complicated, but not too bad. The first step is looking for a pattern to match, which it then pulls from the query. A subsequent step then uses the extracted information to build a filter.
id: string-regexp-extract
title: price less than $X
params:
match:
bind: priceFilter
matchTemplate:
const: price < ${priceValue}
outText:
bind: q
pattern:
const: under (\$|£|)(?P<priceValue>\d+)
text:
bind: q
id: add-filter
title: low price
params:
filter:
bind: priceFilter
condition: priceFilter != ''
This is the power of pipelines: you don’t need to actually write a query, the steps sequentially build it for you.
The above case is looking for a price to be under a dollar amount. Which then removes this text from the query and constructs a filter to ensure the price is under the limit. But equally this can be anything else, colours, sizes, dimensions, anything.
Note here that the first step transformed the initial query and the second step conditionally activates the filter when appropriate. This is interesting as the price input could actually be sent in as part of the initial query (i.e. not extracted). This is a common use case for personalisation and recommendations where the gender, size or preferences may be known.
Product segmentation
If someone searches for “tv” they probably want a tv and not a tv aerial, or a tv cabinet, or something as “seen on tv.” I say “probably” because search and discovery is all about ambiguity. This alignment of queries to some form of segmentation is very valuable. Below shows an example of a query for “tv” both before and after applying a conditional boost to make this alignment.
Before
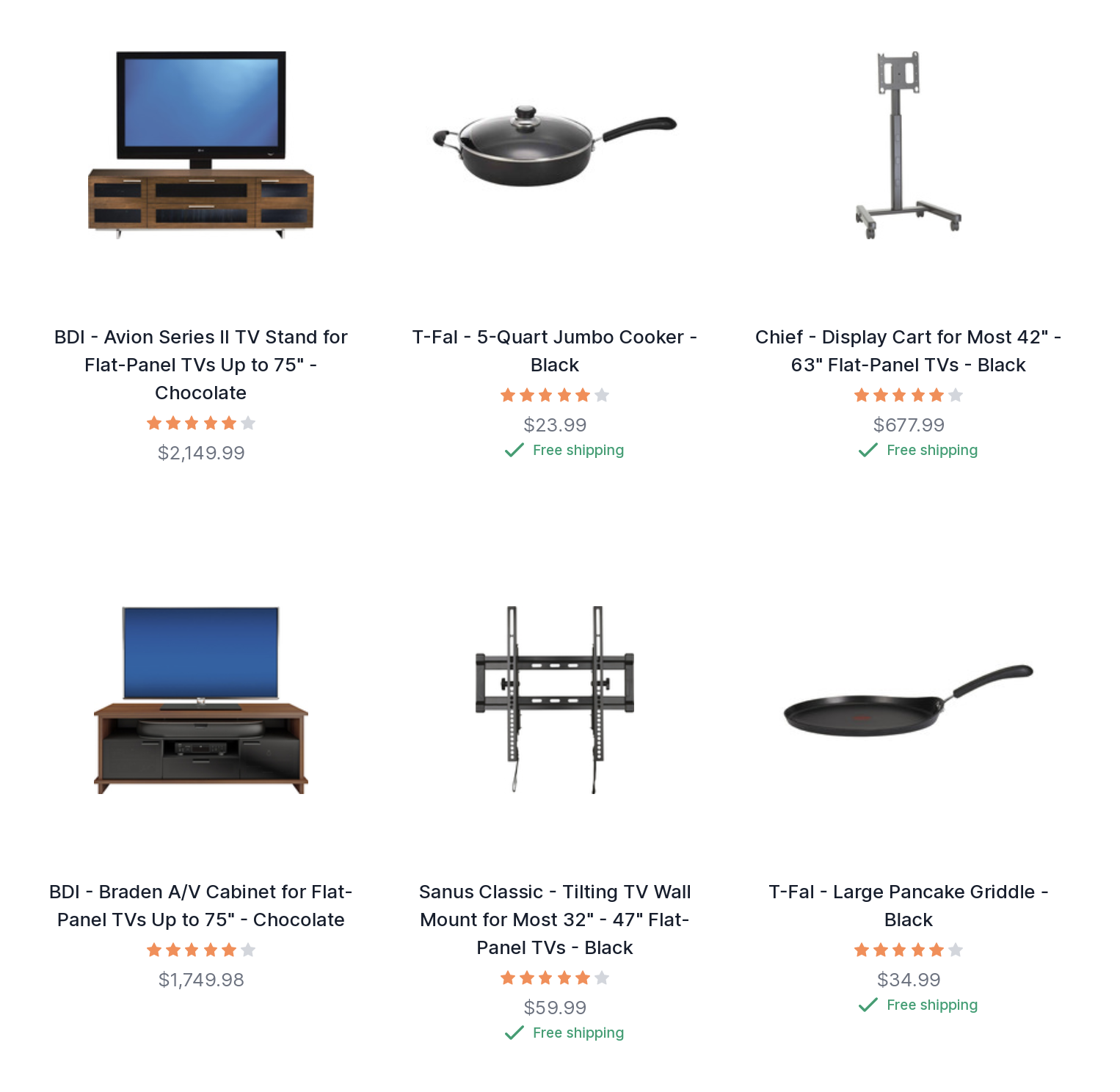
After

The boost is fairly simple. The condition checks to see if the query contains (~) “tv”, if so it then activates and boosts products in the specified category.
id: filter-boost
params:
filter:
const: level2 = 'TV & Home Theater > TVs'
score:
const: "0.2"
condition: q ~ 'tv'
That’s interesting and useful, but obviously difficult to do for many variations right? Actually search.io supports uploading these in bulk in several ways:
Via our API.
Generated from historical performance data automatically
The API is useful if this information already exists in the business (ie, if you already have a solid understanding of what queries are generating purchases, we can import this data for you so you can avoid a “cold start” when migrating to search.io. Contact us for more details).
The analytically generated conditional boosts are far more interesting though, as they can be regenerated automatically using machine learning to dynamically improve your business performance with no effort required.
This example in this demo doesn’t really make use of these as there are no purchases happening! But illustratively you have a couple of options here:
Boost products that outperform for a particular query (note this is done at a product level)
Boost aggregated values based on outperformance for a particular query (note this is looking at aggregated data, e.g. brand, category, gender, etc).
Here’s how it looks in a pipeline.
id: performance-boost
params:
refresh:
const: 6h
interactions:
const: purchase,cart
days:
const: 14
aggregate:
const: level2
score:
const: 0.1
So the step we used previously to boost the tv category would actually now be basically unnecessary, as the performance would create this relationship for all queries with any detected statistically significant relationships. It’s less specific than a hand written rule, but it’s far more accurate than any one person can determine!
Record pipelines
The record pipeline can update and augment information as it is indexed.
Steps can include:
data transformation - e.g. trimming a title
data enrichment - generate a lat and long from an address
classification - labeling content with a category based on an existing model
vectorization - clustering uncategorized records
image recognition - detection of objects and colors, extraction of metadata
For this example build we’re looking at the last example to do with image analysis for visual search which is explained further below.
Visual search
You may have noticed the color palette in the facet and filters menu. This was generated using the Google Cloud Vision API, which is powered by advanced AI image analysis. The color information and image descriptions are AI generated and were not in the original data set.
The image analysis was done as each product was loaded. Uniquely this was done by a pipeline step calling out to a cloud function. Why is that important? Because it shows you can augment product processing with anything you like. Note that these features are available even if you’re using a third-party service such as Shopify to host your store.
Sync product data
There are a couple different ways to sync your data with search.io:
During your initial onboarding, you can submit a JSON file and search.io walks you through a data indexing wizard
You can use our API to load and update data
For this demo, we opted for the latter using our Golang API which neatly uses gRPC.
We could alternatively use the REST API with another supported client language. The format required is fairly simple as much of the complexity is actually handled in the pipeline definitions.
We have had people in the past comment that the updates were too fast to be consistent updates, but they indeed are! We achieve this via upserts to create and sync records The record wasn’t added to a buffer to merge later; instead, the differential was calculated and executed within the request-response sequence. This makes any changes instantly available as soon as they are synchronized. If you’re using ElasticSearch or one of the Lucene variants you will love this feature.
Generating a UI
So far we have ingested and categorized data intelligently, and built smart query pipelines with deep functionality. Now we need to add it to our site and make it shine for a great user experience.
We reference example e-commerce UI code on GitHub here. The demo above is based on this template, but you can also get much more flexible functionality from our React SDK.
This option we chose uses a simple JSON config to setup all the UI elements, which makes the whole interface build take only a few minutes! This is also very lightweight and loads only ~50kB of JavaScript.
JSON config sets up everything.
/**
Your environment configuration
*/
export default {
// These details can be found in your console
projectId: APP_ACCOUNT_ID,
collectionId: APP_COLLECTION_ID,
pipelineName: APP_PIPELINE_NAME,
pipelineVersion: APP_PIPELINE_VERSION,
// For production this can be undefined
endpoint: APP_ENDPOINT,
// Default display type (grid|list)
display: 'list',
// Set the tracking config
tracking: {
field: 'url', // Usually this is 'url'
},
// Which facets to display
// Order in the UI is defined by their order here
// field: Field to use in results
// title: Title to display for the filter
// type: The type of filter to be displayed
// sort: Whether to sort based on the count
facets: [
{ field: 'level1', title: 'Category', sort: true },
{ field: 'brand', title: 'Brand', sort: true },
{ field: 'price_range', title: 'Price', type: filterTypes.price },
{ field: 'imageTags', title: 'Color', type: filterTypes.color },
{ field: 'rating', title: 'Rating', type: filterTypes.rating },
{
field: 'price_bucket',
title: 'Price (bucket)',
buckets: {
high: 'High (Over $200)',
mid: 'Mid ($50 - $200)',
low: 'Low (Under $50)',
},
},
],
// Set buckets to be used as filters
buckets: {
high: 'price >= 200',
mid: 'price >=50 AND price < 200',
low: 'price < 50',
},
// A map for data fields
// If a function is specified, the record data will be passed as the single argument
fields: {
image: 'image',
url: 'url',
title: 'name',
description: 'description',
rating: 'rating',
price: 'price',
freeShipping: 'free_shipping',
category: (data) => data.level4 || data.level3 || data.level2 || data.level1,
},
// Key / Value pairs to add to the request
paramaters: {
// key: 'value',
},
};Note a few things here:
The search facets include several different types (numeric, category, tags and buckets). Buckets allow any filter expression to define a facet grouping so these are highly flexible.
The facets support filtered and non-filtered options. This is important as it allows you to retain the higher level numbers on a single query even when a facet is selected. Unlike many other search providers where this requires two requests!
This supports desktop and mobile layouts responsively
The result layout can be switched from a list to tiled
Multiple different pipelines can be supported (popular, best, price based). In these options the price is a “hard sort” whereas the popularity is a score based “boosted sort” pipeline
In the above example the filter is active, but the other facet counts are still displayed, even though the items are not in the result set. This allows the UI to show the user what else is available, even if not selected. This is optional though.
Conclusion
In less time than it took to write this article we’ve shown how to build a blazing fast e-commerce search and discovery interface with autosuggest, sorting, some basic NLP, machine learning powered automatic result improvement, automated categorical segment alignment, AI generated visual image search, spell correction, gmail style filters, conditional business logic and much more!