How do I whitelist or blacklist so the crawler only adds certain webpages to my index?
The Crawler rules menu allows you create rules to control which pages the crawler visits. They can be based on excluding/including specific domains, subdomains or directories. If the structure of your website hierarchy is not suitable then you can also base rules on data within the HTML. For example you could exclude every page that has a title containing ‘internal only’.
Exclusion example:
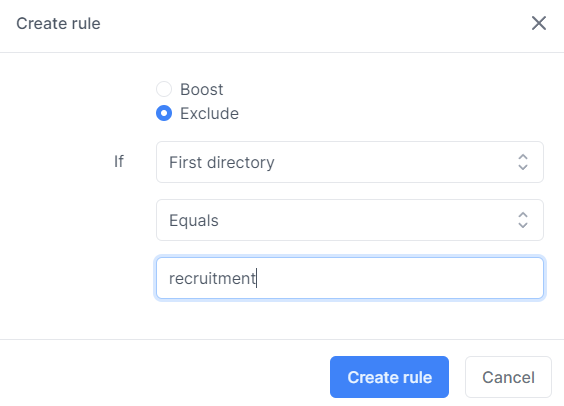
An exclusion rule would be an ideal solution if you had a scenario where you wanted your entire website to be crawled apart from some recruitment information you had in a recruitment subdirectory i.e. www.mywebsite.com/recruitment. Your rule would look like this:

Inclusion example:
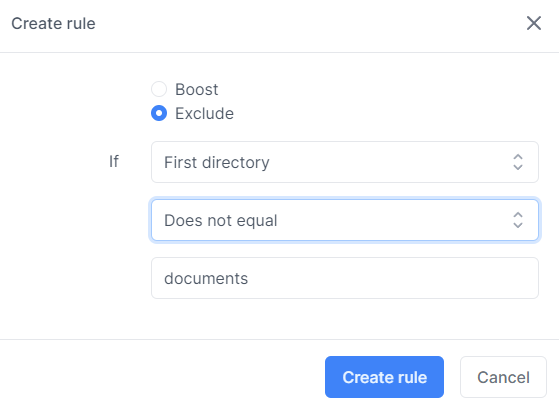
If you only wanted to include webpages from your documents subdirectory (www.mywebsite.com/documents) and exclude everything else then you would create an exclusion rule like the following.